第三期
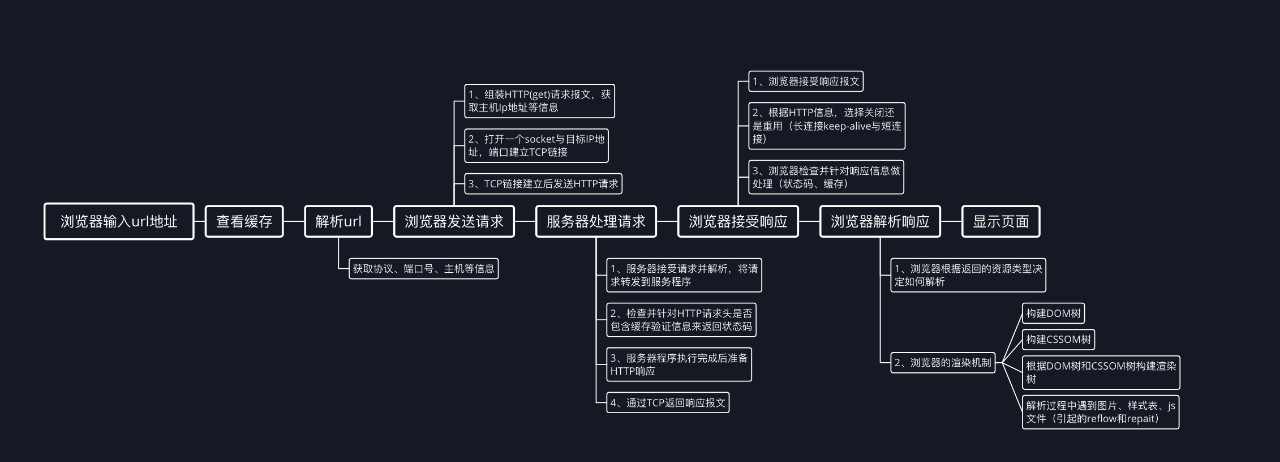
从浏览器地址输入url到显示页面的步骤(Http为例)
浏览器输入url地址;
查看缓存;如果未缓存就发送新请求;缓存会检查HTTP头部信息中的Expires和Cathe-Control;如果缓存失效就发起缓存,如果未失效就使用。(这里可能会涉及到另一个问题:HTTP的缓存机制)
解析URL获取协议、主机、端口等等信息。
浏览器会形成一个HTTP(get)请求报文。
获取主机IP地址以及一些缓存信息。
打开一个socket与目标IP地址,端口建立TCP链接。(进行三次握手)
TCP链接建立后发送HTTP请求。
服务器接受请求并解析,将请求转发到服务程序,如虚拟主机使用HTTP Host头部判断请求的服务程序。
服务器检查HTTP请求头是否包含缓存验证信息如果验证缓存新鲜,返回304等对应状态码。
处理程序读取完整请求并准备HTTP响应,可能需要查询数据库等操作。
服务器将响应报文通过TCP连接发送回浏览器。
浏览器接收HTTP响应,然后根据情况选择关闭TCP连接或者保留重用,关闭TCP连接的四次握手。
浏览器检查响应状态码;如果资源可缓存,进行缓存;对响应进行解码(例如gzip压缩)。
浏览器根据资源类型决定如何解析。(浏览器的渲染机制)
显示页面。
JS的设计模式
设计模式是一种可重用的方案,也可以是我们解决问题的模版。关于设计模式有很多,W3Cschool有一篇文章写关于JS的设计模式,从起初的概念到一些框架和插件的设计都有提到。在这里就简单的提及一下:
常见的模式有工厂模式、单例模式、单体模式、装饰器模式、代理模式、观察者模式、中介者模式、原型模式、命令模式等等。
这些模式都可以优化或解决一些特定的问题,理解并应用它在业务方面会有很大的提升。
比如工厂模式是为了解决多个类似对象声明的问题;也就是为了解决实列化对象产生重复的问题;单体元素可以解决重复创建元素的问题;命令模式简化了复杂的逻辑等等。
排序算法
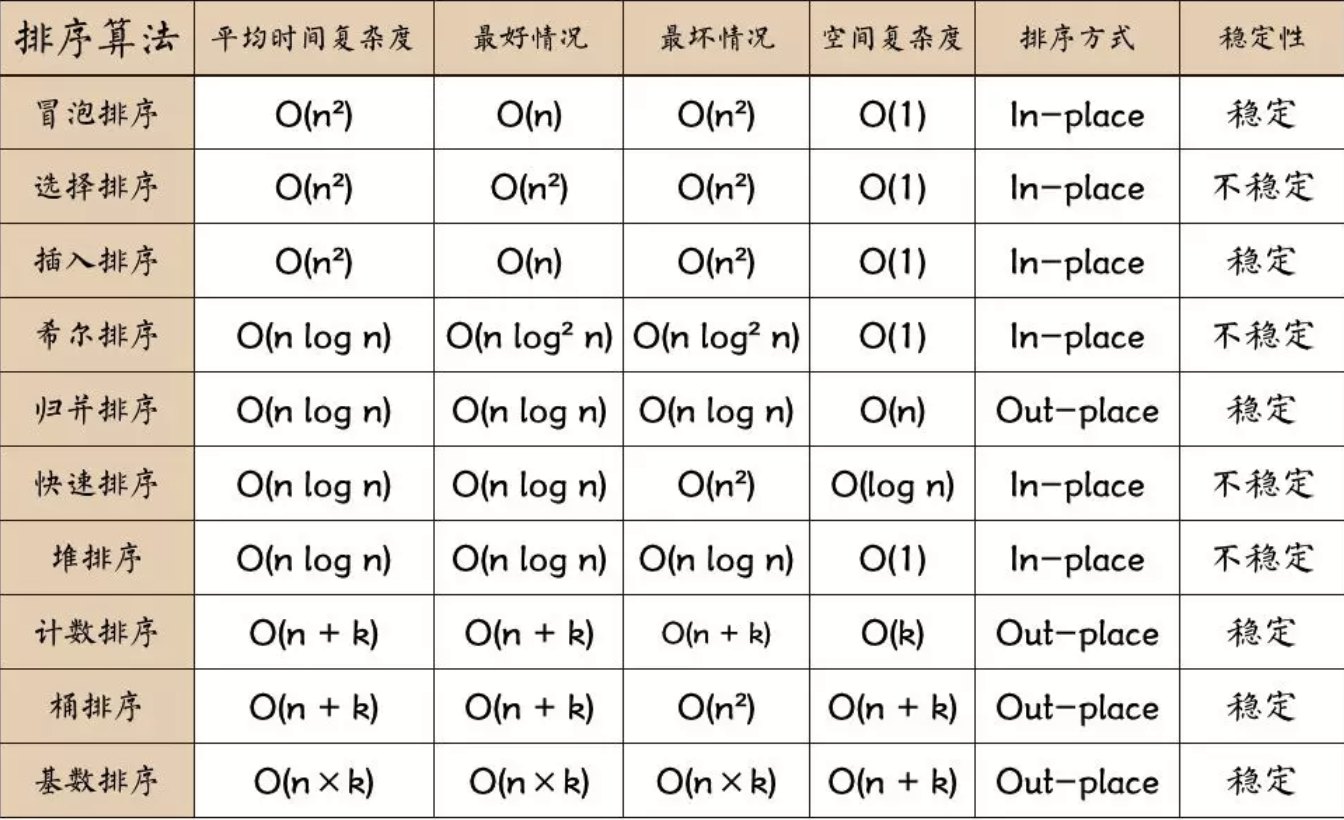
冒泡排序
核心就是相邻元素对比,满足规则互换位置;
如果从小到大排序,它会把最大的一步一步移到最后,逐次进行;
function babblesort(arr) {
let temp = ''
for (let i = 0; i < arr.length - 1; i++) {
for (let j = 0; j < arr.length - 1- i; j++) {
if (arr[j] > arr[j + 1]) {
temp = arr[j]
arr[j] = arr[j + 1]
arr[j + 1] = temp
}
}
}
return arr
}
快速排序
核心就是选取中间值,递归;
选取中间值,创建两个数组,左数组与右数组,小于放左,大于放右;最后递归拼接。
function quicksort(arr) {
if (!arr || !arr.length) return arr;
let middleIndex = Math.floor(arr.length / 2);
let middleItem = arr[middleIndex]
let leftList = [];
let rightList = [];
for (let i = 0; i < arr.length; i++) {
if (arr[i] < middleItem) {
leftList.push(arr[i])
}
if (arr[i] > middleItem) {
rightList.push(arr[i])
}
}
return quicksort(leftList).concat(middleItem, quicksort(rightList))
}
选择排序
核心就是确保当前元素所在位置是最小值;
用当前元素先和之后的元素,取出最小值替换,依次进行。
function selectionSort(arr) {
const len = arr.length;
let minIndex, temp;
for (let i = 0; i < len - 1; i++) {
minIndex = i;
for (let j = i + 1; j < len; j++) {
if (arr[j] < arr[minIndex]) {
minIndex = j;
}
}
temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
return arr;
}
插入排序
核心就是用当前元素先和上一个元素比,如果小于,则互换位置,再继续和上一个元素比,直到它最小。
function insertSort(arr) {
let temp = 0;
for (let i = 1; i < arr.length; i++) {
if (arr[i] < arr[i - 1]) {
temp = arr[i];
let j = i - 1;
arr[i] = arr[j]
while (j >= 0 && temp < arr[j]) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = temp
}
}
return arr
}
希尔排序
核心就是间隔序列的设定;
希尔排序是对插入排序的优化,减少了循环的次数。
function shellSort(arr) {
let len = arr.length,
temp,
gap = 1,
num = 3;
while (gap < len / num) { //动态定义间隔序列
gap = gap * num + 1;
}
for (gap; gap > 0; gap = Math.floor(gap / num)) {
for (let i = gap; i < len; i++) {
temp = arr[i];
let j = i - gap;
for (j; j >= 0 && arr[j] > temp; j -= gap) {
arr[j + gap] = arr[j];
}
arr[j + gap] = temp;
}
}
return arr;
}
归并排序
核心就是分治思想;其实也可以看作是快排的优化,快排的递归深度远大于归并,但它们没有任何关系。
function mergeSort(arr) { //采用自上而下的递归方法
const len = arr.length;
if (len < 2) return arr;
let middle = Math.floor(len / 2),
left = arr.slice(0, middle),
right = arr.slice(middle);
let merge = (leftArry, rightArry) => {
let result = [];
while (leftArry.length && rightArry.length) {
if (leftArry[0] <= rightArry[0]) {
result.push(leftArry.shift());
} else {
result.push(rightArry.shift());
}
}
while (leftArry.length)
result.push(leftArry.shift());
while (rightArry.length)
result.push(rightArry.shift());
return result;
}
return merge(mergeSort(left), mergeSort(right));
}
计数排序
计数排序的核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。
作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
function countingSort(arr) {
let maxValue = Math.max(...arr);
let bucket = new Array(maxValue + 1),
sortedIndex = 0;
arrLen = arr.length,
bucketLen = maxValue + 1;
for (let i = 0; i < arrLen; i++) {
if (!bucket[arr[i]]) {
bucket[arr[i]] = 0;
}
bucket[arr[i]]++;
}
for (let j = 0; j < bucketLen; j++) {
while (bucket[j] > 0) {
arr[sortedIndex++] = j;
bucket[j]--;
}
}
return arr;
}
基数排序
基数排序 vs 计数排序 vs 桶排序
这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
基数排序:根据键值的每位数字来分配桶
计数排序:每个桶只存储单一键值
桶排序:每个桶存储一定范围的数值
function radixSort(arr) {
let [counter, maxDigit, mod, dev] = [[], arr.length, 10, 1];
for (let i = 0; i < maxDigit; i++ , dev *= 10, mod *= 10) {
for (let j = 0; j < arr.length; j++) {
let bucket = parseInt((arr[j] % mod) / dev);
if (counter[bucket] == null) {
counter[bucket] = [];
}
counter[bucket].push(arr[j]);
}
let pos = 0;
for (let j = 0; j < counter.length; j++) {
let value = null;
if (counter[j] != null) {
while ((value = counter[j].shift()) != null) {
arr[pos++] = value;
}
}
}
}
return arr;
}
堆排序
利用堆的概念排序;
堆排序有两种方法:大顶堆和小顶堆。
大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列;
小顶堆:每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列;
function heapSort(arr) {
let len = arr.length;
//替换规则
let swap = (list, i, j) => {
let temp = list[i];
list[i] = list[j];
list[j] = temp;
}
//堆调整
let heapify = (list, i) => {
let left = 2 * i + 1,
right = 2 * i + 2,
largest = i;
if (left < len && list[left] > list[largest]) {
largest = left;
}
if (right < len && list[right] > list[largest]) {
largest = right;
}
if (largest != i) {
swap(list, i, largest);
heapify(list, largest);
}
}
//建立大顶堆
let buildMaxHeap = (list) => {
for (let i = Math.floor(len / 2); i >= 0; i--) {
heapify(list, i);
}
}
buildMaxHeap(arr);
for (let i = arr.length - 1; i > 0; i--) {
swap(arr, 0, i);
len--;
heapify(arr, 0);
}
return arr;
}
桶排序
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。
function bucketSort(arr, bucketSize) {
if (arr.length === 0) {
return arr;
}
let i;
let minValue = arr[0];
let maxValue = arr[0];
for (i = 1; i < arr.length; i++) {
if (arr[i] < minValue) {
minValue = arr[i];//输入数据的最小值
}else if (arr[i] > maxValue) {
maxValue = arr[i];//输入数据的最大值
}
}
//桶的初始化
let DEFAULT_BUCKET_SIZE = 5; //设置桶的默认数量为5
bucketSize = bucketSize || DEFAULT_BUCKET_SIZE;
let bucketCount = Math.floor((maxValue - minValue) / bucketSize) + 1;
let buckets = new Array(bucketCount);
for (i = 0; i < buckets.length; i++) {
buckets[i] = [];
}
//利用映射函数将数据分配到各个桶中
for (i = 0; i < arr.length; i++) {
buckets[Math.floor((arr[i] - minValue) / bucketSize)].push(arr[i]);
}
arr.length = 0;
for (i = 0; i < buckets.length; i++) {
insertSort(buckets[i]); //对每个桶进行排序,这里使用了插入排序
for (let j = 0; j < buckets[i].length; j++) {
arr.push(buckets[i][j]);
}
}
return arr;
}
webpack3和webpack4的区别?以及webpack的构建流程?
先说区别:
- webpack 4引入零配置;
development 模式下,默认开启了NamedChunksPlugin 和NamedModulesPlugin方便调试,提供了更完整的错误信息,更快的重新编译的速度。
production 模式下,由于提供了splitChunks和minimize,所以基本零配置,代码就会自动分割、压缩、优化,同时 webpack 也会自动帮你 Scope hoisting 和 Tree-shaking。
webpack 4 最大的改动就是废除了 CommonsChunkPlugin 引入了 optimization.splitChunks。
修改了对css的支持plugin;原来的extract-text-webpack-plugin让位于mini-css-extract-plugin。
增加了一个mode配置,只有两种值development | production。
废除了UglifyJsPlugin,使用optimization.minimize为true就行。
优化了打包速度,通过 ParallelUglifyPlugin 和 HappyPack 开启多核压缩,提升了打包速度。
...
webpack的构建流程
解析webpack配置参数,合并控制台传入和webpack.config.js文件中的配置参数,产生最后的配置结果
注册配置的插件,让插件监听webpack构建生命周期中的事件节点
从entry入口文件开始解析文件构建语法树,找到每个文件的依赖文件,传递下去
在解析文件递归的过程中,根据文件类型和loader配置来找出合适的loader对文件进行转换
递归完成后得到每个文件的最终结果,根据entry配置生成代码块chunk
输出所有chunk到文件系统
hack原理以及常用的hack
hack原理:利用不同浏览器对CSS的支持和解析结果不一样编写针对特定浏览器样式。
常用的hack有3种:
属性前缀法(类内部hack)
选择器前缀法(选择器hack)
条件注释法
hack其实相当于是欺骗浏览器的行为,不建议使用。